WebAssembly
웹 어셈블리는 브라우저, Node.js 등 JS 런타임에서 네이티브에 가까운 성능으로 코드를 실행할 수 있게 하는 바이트코드 형식의 데이터이다.
주로 JS로 처리하기 버거운 고비용 CPU 연산들을 더 빠르게 처리할 수 있어 이미지/비디오, 렌더링 엔진 등 고성능이 필요한 웹 애플리케이션에서 주로 활용된다. JS 대신 C/C++, Rust 같은 저수준 언어로 작성한 후 .wasm 파일 형식으로 만들어 JS 런타임에서 실행할 수 있다.
WebAssembly가 JS보다 빠른 이유는 여러 가지인데, 대표적으로 정적 타입 언어의 최적화, 바이트 코드의 불필요한 파싱, 가비지 콜렉션 없음 등이 있다.
또한 WebAssembly를 활용하면 JS가 아닌 다른 언어로 작성된 라이브러리들을 wasm으로 컴파일하여 바로 사용할 수 있다는 것도 장점이다. 그래서 FFmpeg, OpenCV 와 같이 기존 C/C++로 작성된 유용한 라이브러리들을 그대로 활용할 수 있다.
이미지 필터 적용을 통해 성능 벤치마크하기
실제 사용 서비스에서 WebAssembly를 활용할 만큼 고성능 연산이 필요한 비즈니스 요구사항은 그렇게 많은 편이 아니다. 따라서 간단히 WebAssembly를 체험해 볼 목적으로 이미지 필터 적용이라는 주제를 이용해 JS와의 성능 차이를 벤치마크해보았다.
참고로 이미지 필터 알고리즘의 경우 WebGL 등을 활용하여 CPU가 아닌 GPU로 병렬처리하는 것이 훨씬 효율적이다. 그렇지만 흥미로운 주제로 비교해보고 싶어 이 주제를 선택하였다.
테스트에 사용할 이미지는 4032x3024 해상도로, 약 12,000,000 개의 픽셀로 이루어져있다. 각 필터 알고리즘은 이 픽셀 배열을 순회하며 연산을 수행한다.
WebAssembly와 JS연결
WebAssembly에서 사용할 코드는 Rust로 작성하였다.
이 Rust 코드를 JS에서 활용하기 위해서는 브라우저에서 사용할 수 있는 .wasm 파일 형식으로 컴파일해야 한다.
이를 위해 wasm-bindgen 크레이트와 wasm-pack CLI 도구를 활용하였다.
wasm-bindgen
Rust로 작성한 코드 중에 wasm 파일을 통해 JS로 사용할 수 있도록 export 해야할 함수들이 있을 것이다.
wasm-bindgen 크레이트를 설치하고, export 대상 함수들에 #[wasm-bindgen] attribute 매크로를 추가하면 된다.
rustuse wasm_bindgen::prelude::wasm_bindgen; #[wasm_bindgen] pub fn grayscale_wasm(pixels: &mut [u8]) { for chunk in pixels.chunks_exact_mut(4) { let r = (chunk[0] as u32) * 306; // 0.299 * 1024 let g = (chunk[1] as u32) * 601; // 0.587 * 1024 let b = (chunk[2] as u32) * 117; // 0.114 * 1024 let luma = ((r + g + b) >> 10) as u8; chunk[0] = luma; chunk[1] = luma; chunk[2] = luma; } }
wasm-bindgen은 이 매크로가 붙은 함수에 대해 JS와 Rust 사이의 인터페이스 역할을 하는 메타데이터를 생성한다. 세부적으로는 JS 글루코드와 TS 타입 정의, 그리고 메모리 관리 및 타입 변환 코드를 자동으로 생성해준다고 보면 된다.
wasm-pack
wasm-pack은 Rust 파일 컴파일과 JS 바인딩을 한 번에 실행해주는 CLI 도구이다.
bash# cargo build + binding 한 번에 수행 wasm-pack build --target web --release
패키징된 결과에는 다음 파일들이 존재한다.
{project_name}.js- JS 글루코드{project_name}.d.ts- TS 타입 정의{project_name}.wasm- 컴파일된 WebAssembly 바이너리{project_name}.wasm.d.ts- Wasm 모듈 타입 정의
Grayscale 필터 적용하기

먼저 Grayscale 필터를 적용해보았다. Grayscale 적용 방법은, RGB 값으로 luma 값(정규화된 가중 평균)을 계산하고, 그 결과를 각 RGB 채널에 대입해주면 된다.
픽셀 배열을 순회하면서 연산 후 요소를 수정만 하면 되기 때문에 O(n)의 시간복잡도로 처리할 수 있다.
성능 측정 결과는 다음과 같다.
JavaScript: 평균 23ms
WebAssembly: 평균 10ms
속도 향상: 약 2.3배
부동 소수점 연산 오버헤드
처음에 grayscale Rust 코드를 작성하고 JS와 비교했을 때 사실 JS의 실행 속도가 더 빠른 것이 확인되어 당황했었다. 알고 보니 이유는 단순했는데, luma 값 연산이 부동 소수점 연산으로 수행되었기 때문이었다. JS 엔진의 JIT 컴파일러가 반복되는 부동 소수점 연산을 런타임에 최적화하는 반면, WebAssembly 코드는 그렇지 못했을 가능성이 있다.
js// luma value 계산 r * 0.299 + g * 0.587 + b * 0.114
픽셀의 각 RGB 채널의 값은 0~255 사이의 정수인데, 0.299 같은 가중치와 연산하려면 RGB 정수 타입이 부동소수 타입으로 캐스팅된 후 부동소수 연산이 이뤄지게 된다. 그러나 부동소수 연산은 정수 연산에 비해 곱셈은 3-5배, 덧셈은 약 2-3배 느리다고 한다. 따라서 천만 번 이상의 부동소수 연산을 정수 연산으로 바꿔주면 훨씬 빨라질 수 있는 것이었다.
이를 위해 가중치에 일정 값을 곱해 정수로 근사시켜 정수 연산으로 바꿔주었다. 그리고 마지막에 가중치에 곱해준 값만큼 나눠줘야 하는데, 여기서도 일반 나눗셈보다 비트 시프트 연산이 5배 정도 빠르다고 한다. 따라서 가중치들에 1024를 미리 곱해주고 마지막에 비트 시프트를 하는 형태로 바꿔주었다.
js(r * 306 + g * 601 + b * 117) >> 10
JS, Rust 모두 정수 연산으로 바꿔준 결과, 웹 어셈블리가 약 2.3배 빠른 것을 확인할 수 있었다.
가우시안 블러 필터 적용하기

가우시안 블러(Gaussian Blur) 기법은 주변 픽셀과의 거리를 기반으로 가우시안 분포를 갖는 K x K 커널로 각 픽셀에 가중 평균을 적용해 흐림 효과를 생성하는 방법이다.
그러나 실제로 2차원 커널을 사용하면 너무 느리기 때문에, 박스 블러(Box Blur) 기법을 여러번 중첩하여 가우시안 분포에 가까워지도록 만드는 방식을 사용하였다.
박스 블러는 슬라이딩 윈도우 방식으로, 정사각형 영역의 픽셀들의 평균값을 계산해 중심 픽셀에 반영하는 방식이다.
그리고 이 슬라이딩 윈도우도 수평/수직 방향으로 분리하여 계산하면 m x m의 연산을 m x 2로 줄일 수 있다.
따라서 수평/수직으로 박스 블러를 1회 적용하는 것을 3번 반복하면 n * 6번의 연산만으로 가우시안 블러를 구현할 수 있다.
성능 측정 결과는 다음과 같다.
JavaScript: 평균 450ms
WebAssembly: 평균 280ms
속도 향상: 약 1.6배
웹 어셈블리의 lazy compilation
웹 어셈블리는 사실 완전히 컴파일된 코드는 아니고, 중간 단계의 바이너리 데이터이다. JS 런타임에서 실행되기 위해 네이티브 기계어로 한 번 더 컴파일되어야 한다. 이 작업은 브라우저의 JS엔진이 수행한다.
그럼에도 .wasm 파일은 이미 바이너리 코드이므로 별도 파싱 과정 없이 디코딩만 하면 된다.
또한 정적 타입 언어로 작성되므로, 일반 JS보다 더 최적화되기 쉬운 저수준 형태로 되어있어 성능 측면에서 JS보다 유리하다.
JS도 순수 인터프리트 형태는 아닌데, 현대 자바스크립트 엔진(ex. V8, SpiderMonkey)은 컴파일 + 인터프리트의 하이브리드 방식을 사용하기 때문이다. V8 엔진 기준으로, Ignition 인터프리터는 소스코드를 파싱한 후 AST(추상 구문 트리) 형태로 변환하고 바이트코드로 컴파일한다.
그러나 WebAssembly와 다르게 파싱 단계가 필요하고, 또 동적 언어의 특성 상 타입을 미리 알 수 없어 런타임 체크가 필요한 부분이 많다는 특징이 있다.
Liftoff 컴파일의 lazyness
벤치마크를 하면서 문제되는 현상이 하나 있었는데, 바로 WebAssembly 함수의 첫 호출이 항상 다음 호출보다 느린 것이었다. 첫 함수 호출은 다음 호출보다 약 2~2.5배 정도 느렸고, 이로 인해 JS와의 성능 차이가 없거나 오히려 더 느렸다.
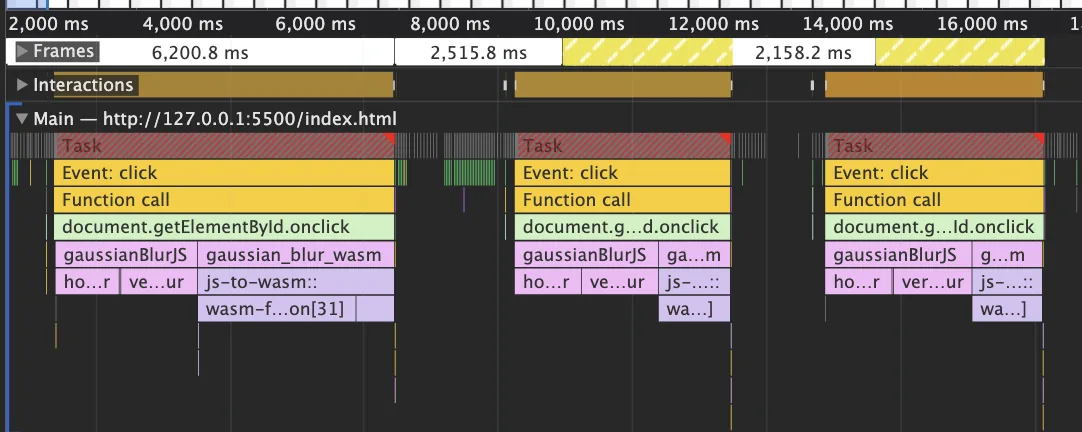
문제의 원인은 바로 WebAssembly 컴파일이 lazy하게 수행되기 때문이었다. 크롬 V8 엔진의 웹 어셈블리 컴파일 문서를 확인해보면 다음과 같이 나와있다.
Initially, V8 does not compile any functions in a WebAssembly module. Instead, functions get compiled lazily with the baseline compiler Liftoff when the function gets called for the first time
즉 초기에는 모든 WebAssembly 함수들을 컴파일하지 않고, 대신 첫 호출 시 lazy하게 컴파일한다는 것이다. 그래서 항상 첫 호출은 컴파일 단계를 포함하여 느리고, 이후 호출부터는 이미 컴파일된 코드를 가져다 쓰므로 확실히 빠른 것이었다.
Once Liftoff compilation is finished, the resulting machine code gets registered with the WebAssembly module, so that for future calls to the function the compiled code can be used immediately.
최적화를 위한 warm-up
벤치마크에서는 최적화된 performance 기준으로 비교해보고 싶었고, 또 각 수행 결과들의 일관성을 보장하기 위해 페이지 로드와 함께 각 필터 함수들을 미리 호출하여 warm up 을 수행하였다.
이 때, 사전에 함수 호출만 해둔다고 문제가 해결되는 것은 아니었다. 함수 호출 시 수행하는 연산이 너무 작으면, 2번째 호출 시에도 최적화된 결과를 확인할 수 없었다.
예상컨대 lazy compilation 전략이 어느 정도는 휴리스틱하게 작동하도록 설계되어 있는 것 같다. 따라서 너무 작은 데이터가 아닌 적정 크기의 데이터로 warm up 해주었더니 의도대로 동작하였다.
js// Initialize WASM when DOM is ready document.addEventListener("DOMContentLoaded", async () => { await init(); // 적정 크기의 데이터로 warm up grayscale_wasm(new Uint8ClampedArray(500000)); gaussian_blur_wasm(new Uint8ClampedArray(40000), 100, 100); });
DevTools의 최적화 tiered-down
참고로 디버깅에 어려움을 겪었던 것이 하나 더 있었는데 바로 개발자 도구(DevTools)를 열면 Liftoff 컴파일의 최적화 효과가 적용되지 않는 것이었다. 이것도 크롬 공식 문서를 확인해보니 개발자 도구를 키면 정확한 디버깅을 위해 적용되었던 optimization들이 tiered-down 된다는 것이었다.
When you open DevTools, WebAssembly code gets "tiered down" to an unoptimized version to enable debugging.
Tiered-down 적용 없이 순수 real-world performance를 확인하고 싶으면 Performance Panel에서 recording을 활용하거나, 먼저 동작 시뮬레이션 후 devTools를 열 것을 권장하고 있다.
SIMD 최적화
웹 어셈블리를 사용할 때 성능을 더 극대화하는 방법이 있는데 SIMD(Single Instruction, Multiple Data) 병렬 처리 기법이다. 이름 그대로 하나의 명령을 사용하여 여러 데이터를 동시에 처리할 수 있는 방법이다.
SIMD는 CPU의 벡터 레지스터를 활용하여 동작한다. 일반 스칼라 연산이 한 번에 하나의 값만 처리하는 것과 달리, SIMD는 128비트 크기의 벡터 레지스터에 여러 데이터를 로드한 후 단일 명령으로 병렬 연산을 수행한다.
일반적인 연산 원리와 비교하면 다음과 같다.
python# 단순 연산 a = [1, 2, 3, 4] b = [5, 6, 7, 8] result = [] for i in range(4): result[i] = a[i] + b[i] # 4번의 개별 연산 # SIMD 병렬 연산 a = [1, 2, 3, 4]; # 128비트 벡터 b = [5, 6, 7, 8]; # 128비트 벡터 result = a + b; # 단 1번의 벡터 연산
SIMD 연산은 이미지 필터 연산에 활용하기에 매우 적합한 방식이다. 하나의 픽셀은 4개의 RGBA 채널 요소로 구성되는데, SIMD를 활용하면 각 채널을 개별적으로 연산하는 대신 픽셀 단위로 연산할 수 있다. 여기서 더 나아가 128비트 벡터 레지스터를 사용하면 최대 4개의 픽셀(16바이트)까지 동시에 처리할 수 있다.
다만 SIMD 적용을 위해 코드가 굉장히 장황해지므로, 어느정도 trade-off가 존재한다.
마무리
실험 결과를 통해 WebAssembly 사용 시 2배 전후의 성능 향상 이점을 얻을 수 있다는 것을 확인하였다.
한 가지 걸리는 것은 최초 호출 시의 지연이다. 가우시안 블러에서 오히려 JS보다 느린 결과를 얻었기 때문에, 실제 프로덕션 환경에서는 사용한다면 warm-up 전략을 충분히 고려해야 될 것이다.
그럼에도 SIMD 최적화, 멀티스레드와 같은 이점도 최대한 활용한다면 특정 영역에서 더욱 유용하게 활용할 수 있을 것으로 보인다.
참고 자료
https://v8.dev/docs/wasm-compilation-pipeline
https://developer.chrome.com/blog/wasm-debugging-2020?hl=en
https://www.zigae.com/chrome-gc/
https://www.pooolingforest.com/blog/compiler-auto-vectorization-simd-performance-893